
Web crawler adalah suatu program atau script otomat yang relatif simple, yang dengan metode tertentu melakukan scan atau “crawl” ke semua halaman-halaman Internet untuk membuat index dari data yang dicarinya.
Apa yang dimaksud dengan web crawler ?
Web crawler adalah suatu program atau script otomat yang relatif simple, yang dengan metode tertentu melakukan scan atau “crawl” ke semua halaman-halaman Internet untuk membuat index dari data yang dicarinya.
Apa yang dimaksud dengan web crawler ?
Web Cewler adalah sebuah program dengan metode tertentu yang berfungsi untuk melakukan Scan atau crawl ke semua halaman internet untuk mencari data yang diinginkan. Data tersebut merupakan hasil teratas dari mesin pencari google dan yahoo. Web Crawler atau web spider, web robot, bot crawl dan automathic indeker. Web clawer memiliki beberapa maafaat dan tujuan tetapi penggunaan yang paling umum digunakan sebagai search engine. Search engine merupakan sebuah tool yang berfungsi sebagai mesin pencari seperti google. Web ini dapat diakses pada alamat www.webclawler.com
Sejarah
Web clawler adalah mesin pencari Web pertaman yang menyediakan pencarian teks penuh dan lengkap. awalnya web clewler adalah sebuah aplikasi desktop yang diciptakan oleh Brian Pinkerton, seorang mahasiswa CSE di University of Washington pada tanggal 20 april 1994.
Web crawler awalnya mesin pencari dengan database sendiri dan ditampilkan hasil iklan diwilayah yang terpisah dari halaman dan baru baru ini telah direposisi sebagai mesin metasearch. Pada tanggal 1 Juni 1995 web ini di beli oleh Amarican online dan pada saat akuisisi web crawler penggunanya tidak lebih dari 1 juta pengguna dan dijual kepada excite pada tanggal 1 april 1997. Kemudian pada tahun 2001 web cawler diakuisisi oleh Infospace stelah excite (kemudian sekarang disebut Excite @Home).
Pada tahun 2008 web crawler mengubah citranya dan terjadi Scrapping maskot laba laba klasik. Sehungga pada tahun 2010 web crawler dapat menduduki peringkat 753 paling populer di Amerika Serikat dan 2994 piling terpopuler di dunia oleh Alexa. Pada tahun yang sama pengunjung web clawler diperkiraan mencapai 1,7 juta pengunjung perbulan.
Kelebihan
Suatu program atau script yang relatif simple Proses sebuah web crawler untuk mendata link – link yang terdapat didalam sebuah halaman web menggunakan pendekatan regular expression. Crawler akan menelurusi setiap karakter yang ada untuk menemukan hyperlink tag html. Setiap hyperlink tag yang ditemukan diperiksa lebih lanjut apakah tag tersebut mengandung atribut nofollow rel, jika tidak ada maka diambil nilai yang terdapat didalam attribute href yang merupakan sebuah link baru.
Dapat digunakan untuk beragam tujuan. Penggunaan yang paling umum adalah yang terkait atau berhubungan langsung dengan search engine.
Kekurangan
Mengingat dia sejatinya mesin atau program, kita mesti menyesuaikan (semisal konten yang berguna) agar web crawler juga tahu bahwa halaman yang sedang dijelajahinya berisi informasi bermanfaat. Sebab, mesin web crawlerc menandai proses-proses tertentu dalam situs sebagai kelemahan. Misalnya, halaman-halaman yang lamban saat dipanggil mungkin dilewati begitu saja. Atau, lantaran konfigurasi situs tidak terlalu bagus membuat si web crawler kurang efisien kala mengeksplorasi. Lalu, dia lebih fokus pada beberapa halaman dan melewatkan yang lain padahal mungkin isinya penting. Ini akan menjadi tantangan tersendiri bagi situs ritel besar yang banyak mengandung konten dinamis, yaitu halaman web yang kompleks (misalnya konten yang dipersonalisasi).
Sistem Pencarian di web Crawler
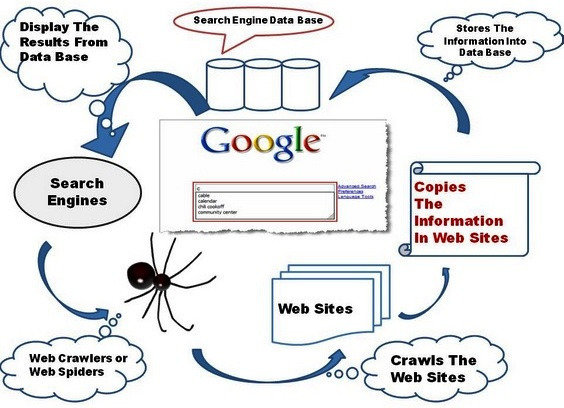
crawler ini memindai halaman web untuk melihat kata-kata apa yang dikandungnya, dan di mana kata-kata yang digunakan. crawler berubah temuannya ke indeks raksasa. Indeks pada dasarnya adalah daftar besar dari kata-kata dan halaman web yang menampilkan mereka. Jadi ketika Anda meminta mesin pencari untuk halaman tentang kuda nil, mesin pencari memeriksa indeks dan memberikan daftar halaman yang menyebutkan kuda nil. web crawler memindai web secara teratur sehingga mereka selalu memiliki indeks up-to-date dari web.
Web Crawler atau Web Spider berarti menyimpan halaman website yang telah dibuka ke database, lalu web spider akan mencari link-link yang terhubung secara terus menerus hingga seluruhnya masuk ke database dan menyimpannya juga, membentuk indeks pada halaman yang didownload sehingga mempercepat proses pencarian. Fungsi Web Crawlers yang lainnya yaitu untuk pemeliharaan otomatis suatu situs web, seperti memeriksa link atau validasi kode HTML. Selain itu juga bisa untuk mengumpulkan tipe-tipe informasi spesifik dari halaman web; misalnya memungut alamat e-mail seperti spam.