
Data mining sangat perlu dilakukan terutama dalam mengelola data yang sangat besar untuk memudahkan aktifitas recording suatu transaksi dan untuk proses data warehousing agar dapat memberikan informasi yang akurat bagi penggunanya.
Data mining sangat perlu dilakukan terutama dalam mengelola data yang sangat besar untuk memudahkan aktifitas recording suatu transaksi dan untuk proses data warehousing agar dapat memberikan informasi yang akurat bagi penggunanya.
Data Mining adalah serangkaian proses untuk menggali nilai tambah berupa informasi yang selama ini tidak diketahui secara manual dari suatu database dengan melakukan penggalian pola-pola dari data dengan tujuan untuk memanipulasi data menjadi informasi yang lebih berharga yang diperoleh dengan cara mengekstraksi dan mengenali pola yang penting atau menarik dari data yang terdapat dalam basisdata.
Ada beberapa definisi dari data mining yang dikenal di buku-buku teks data mining, diantaranya adalah :
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual.
Data mining adalah analisa otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya
Dari definisi-definisi itu, dapat dilihat ada beberapa faktor yang mendefinisikan data mining :
Kehadiran data mining dilatarbelakangi dengan problema data explosion yang dialami akhir-akhir ini dimana banyak organisasi telah mengumpulkan data sekian tahun lamanya (data pembelian, data penjualan, data nasabah, data transaksi dsb.)
Proses penemuan pola yang menarik dari data yang tersimpan dalam jumlah besar.
Ekstraksi dari suatu informasi yang berguna atau menarik (non-trivial, implisit, sebefumnya belum diketahui potensial kegunaannya) pola atau pengetahuan dari data yang disimpan dalam jumlah besar.
Ekplorasi dari analisa secara otomatis atau semiotomatis terhadap data-data dalam jumlah besar untuk mencari pola dan aturan yang berarti.
Datamining adalah suatu proses yang berasal dari rangkaian-rangkaian proses, sebagai berikut :
Data cleaning (untuk menghilangkan noise data yang tidak konsisten) Data integration (di mana sumber data yang terpecah dapat disatukan)
Data selection (di mana data yang relevan dengan tugas analisis dikembalikan ke dalam database)
Data transformation (di mana data berubah atau bersatu menjadi bentuk yang tepat untuk menambang dengan ringkasan performa atau operasi agresi)
Knowledge Discovery (proses esensial di mana metode yang intelejen digunakan untuk mengekstrak pola data)
Pattern evolution (untuk mengidentifikasi pola yang benar-benar menarik yang mewakili pengetahuan berdasarkan atas beberapa tindakan yang menarik)
Knowledge presentation (di mana gambaran teknik visualisasi dan pengetahuan digunakan untuk memberikan pengetahuan yang telah ditambang kepada user).
SUMBER :
Data mining adalah sebuah proses komputasi mengekstrak informasi dari kumpulan data yang besar kemudian mengubahnya menjadi struktur yang mudah dipahami dibantu dengan berbagai alat analisis data, dimana bertujuan untuk menemukan pola lalu menghubungkannya ke dalam data yang melibatkan metode cerdas, statistik, dan sistem database untuk membuat prediksi yang valid/benar.
Dalam data mining, aturan asosiasi dibuat dengan menganalisis data untuk pola if / then yang sering, kemudian menggunakan kriteria dukungan dan kepercayaan untuk menemukan hubungan terpenting dalam data. Dukungan adalah seberapa sering item muncul di database, sementara kepercayaan adalah berapa kali jika/maka pernyataan akurat.
Hasil dari data mining didapatkan dari langkah menganalisis data mentah yang melibatkan aspek pengelolaan data dan database, pra-pengolahan data, pertimbangan model dan pertimbangan, metrik yang menarik, pertimbangan kompleksitas, pemrosesan postingan struktur, visualisasi, dan pemutakhiran yang telah ditemukan.
Tugas penggalian data sebenarnya merupakan analisis semi otomatis atau otomatis dari sejumlah besar data untuk mengekstrak pola yang tidak diketahui sebelumnya, seperti pola catatan data (analisis cluster), rekaman yang tidak biasa (deteksi anomali), dan dependensi (aturan asosiasi penggalian, penggalian pola berurutan). Ini biasanya melibatkan penggunaan teknik database seperti indeks spasial. Pola ini kemudian dapat dilihat sebagai semacam ringkasan data masukan, dan dapat digunakan dalam analisis lebih lanjut.
Refrensi : What is Data Mining?
Pengertian data mining berdasarkan (JK06) adalah proses mengekstraksi pola-pola yang menarik (tidak remeh-temeh, implisit, belum diketahui sebelumnya, dan berpotensi untuk bermanfaat) dari data yang berukuran besar.
Definisi data mining dari Adelman. pengertian data mining adalah proses pencarian pola data yang tidak diketahui atau tidak diperkirakan sebelumnya.
Pengertian data mining menurut Gartner Group, data mining sebagai suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa dalam sekumpulan besar data yg tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik statisik dan matematika.
Data yang diperoleh pada data mining biasanya diperoleh dari data data yang telah ada sebelumnya atau bisa juga melalui survey survey tertentu. Kemudian data tersebut dianalisis untuk menemukan pola pola yang menarik kemudian divisualisasikan untuk memberikan informasi kepada user.
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database . Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar. (Turban, dkk. 2005)
Definisi umum dari data mining itu sendiri adalah proses pencarian pola-pola yang tersembunyi ( hidden patern ) berupa pengetahuan ( knowledge ) yang tidak diketahui sebelumnya dari suatu sekumpulan data yang mana data tersebut dapat berada di dalam database , data werehouse , atau media penyimpanan informasi yang lain.
Hal penting yang terkait di dalam data mining adalah:
Data mining merupakan suatu proses otomatis terhadap data yang sudah ada.
Data yang akan diproses berupa data yang sangat besar.
Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
Data mining dilakukan dengan tool khusus, yang mengeksekusi operasi data mining yang telah didefinisikan berdasarkan model analisis. Data mining merupakan proses analisis terhadap data dengan penekanan menemukan informasi yang tersembunyi pada sejumlah data besar yang disimpan ketika menjalankan bisnis perusahaan.
Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor antara lain:
Pertumbuhan yang cepat dalam kumpulan data.
Penyimpanan data dalam data warehouse , sehingga seluruh perusahaan memiliki akses ke dalam database yang andal.
Adanya peningkataan akses data melalui navigasi web dan internet.
Tekanan kompetisi bisnis untuk meningkatkan penguasaan pasar dalam globalisasi ekonomi.
Perkembangan teknologi perangkat lunak untuk data mining (ketersediaan teknologi.
Perkembangan yang hebat dalam kemampuan komputasi dan pengembangan kapasitas media penyimpanan. (Larose, 2005)
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lainnya. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining.
Proses KDD ada 5 tahapan yang dilakukan secara terurut, yaitu:
Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang digunakan untuk proses data mining , disimpan dalam suatu berkas, terpisah dari basis data operasional.
Pre-processing / cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data.
Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining . Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keselurahan.
Interpretation / evalution
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagaian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang d item ukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya. (Fayyad, 1996)
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu:
Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecendrungan yang terdapat dalam data. Sebagai contoh, petugas pengumpul suara mungkin tidak menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecendrungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecendrungan.
Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori. Model dibangun dengan record lengkap menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
Pengklusteran
Pengklusteran merupakan pengelompokan record , pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain.
Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja ( market basket analysis ). (Larose,2005)
Arsitektur utama dari sistem data mining , pada umumnya terdiri dari beberapa komponen sebagai berikut:
Basis data (Database), data warehouse , atau media penyimpanan informasi, terdiri dari satu atau beberapa database , data warehouse , atau data dalam bentuk lain. Pembersihan data dan integrasi data dilakukan terhadap data tersebut. Database, data warehose , bertanggung jawab terhadap pencarian data yang relevan sesuai dengan yang diinginkan pengguna atau user .
Basis pengetahuan ( Knowledge Base ), merupakan basis pengetahuan yang digunakan sebagai panduan dalam pencarian pola.
Data mining engine, merupakan bagaian penting dari sistem dan idealnya terdiri dari kumpulan modul-modul fungsi yang digunakan dalam proses karakteristik ( characterization ), klasifikasi ( clasiffication ), dan analisis kluster ( cluster analysis ). Dan merupakan bagian dari software yang menjalankan program berdasarkan algoritma yang ada.
Evaluasi pola ( pattern evaluation ), komponen ini pada umumnya berinteraksi dengan modul-modul data mining . Dan bagian dari software yang berfungsi untuk menemukan pattern atau pola-pola yang terdapat dalam database yang diolah sehingga nantinya proses data mining dapat menemukan knowledge yang sesuai.
Antar muka ( Graphical user interface ), merupakan modul komunikasi antara pengguna atau user dengan sistem yang memungkinkan pengguna berinteraksi dengan sistem untuk menentukan proses data mining itu sendiri.
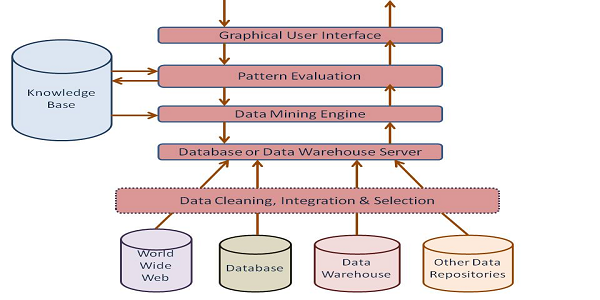
Gambar Arsitektur Data mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005).
Definisi umum dari data mining itu sendiri adalah proses pencarian pola-pola yang tersembunyi (hidden patern) berupa pengetahuan (knowledge) yang tidak diketahui sebelumnya dari suatu sekumpulan data yang mana data tersebut dapat berada di dalam database, data werehouse, atau media penyimpanan informasi yang lain. Hal penting yang terkait di dalam data mining adalah:
Data mining dilakukan dengan tool khusus, yang mengeksekusi operasi data mining yang telah didefinisikan berdasarkan model analisis. Data mining merupakan proses analisis terhadap data dengan penekanan menemukan informasi yang tersembunyi pada sejumlah data besar yang disimpan ketika menjalankan bisnis perusahaan. Kemajuan luar biasa yang terus berlanjut dalam bidang data mining didorong oleh beberapa faktor antara lain:
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lainnya. Salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD itu ada 5 tahapan yang dilakukan secara terurut, yaitu:
Data selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
Pre-processing / cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data.
Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keselurahan.
Interpretation / evalution
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagaian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya. (Fayyad, 1996)
Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu:
Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecendrungan yang terdapat dalam data. Sebagai contoh, petugas pengumpul suara mungkin tidak menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecendrungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecendrungan.
Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik dari pada ke arah kategori. Model dibangun dengan record lengkap menyediakan nilai dari variabel target sebagai nilai prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nilai variabel prediksi.
Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori. Sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan dengan record-record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variabel target dalam pengklusteran. Pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variabel target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keseluruhan data menjadi kelompok-kelompok yang memiliki kemiripan record dalam satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang belanja (market basket analysis) (Larose,2005).