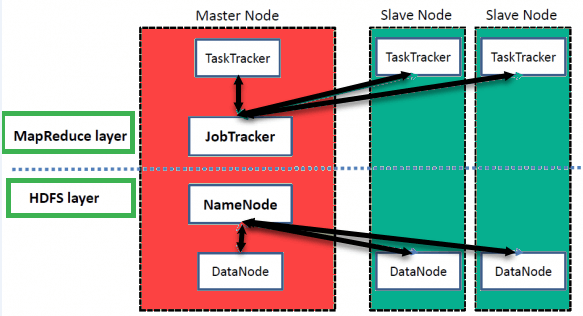
Hadoop memiliki Arsitektur Master-Slave untuk penyimpanan data dan pemrosesan data terdistribusi menggunakan metode MapReduce dan HDFS.
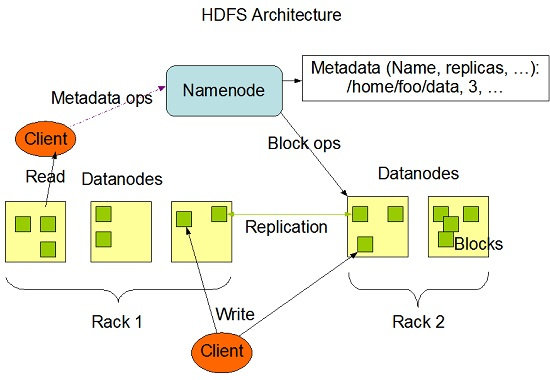
NameNode:
NameNode mewakili setiap file dan direktori yang digunakan di namespace
DataNode:
DataNode membantu Anda mengelola keadaan simpul HDFS dan memungkinkan Anda berinteraksi dengan blok
MasterNode:
Node master memungkinkan Anda untuk melakukan pemrosesan paralel data menggunakan Hadoop MapReduce.
Slave Node:
Node slave adalah mesin tambahan di cluster Hadoop yang memungkinkan Anda menyimpan data untuk melakukan perhitungan yang rumit. Terlebih lagi, semua slave node hadir dengan Task Tracker dan DataNode. Ini memungkinkan Anda untuk menyinkronkan proses dengan NameNode dan Job Tracker masing-masing.
Di Hadoop, sistem master atau slave dapat diatur di cloud atau di tempat
Fitur ‘Hadoop’
• Cocok untuk Analisis Big Data
Karena Big Data cenderung didistribusikan dan tidak terstruktur, cluster HADOOP paling cocok untuk analisis Big Data. Karena memproses logika (bukan data aktual) yang mengalir ke node komputasi, bandwidth jaringan lebih sedikit dikonsumsi. Konsep ini disebut sebagai konsep lokalitas data yang membantu meningkatkan efisiensi aplikasi berbasis Hadoop.
• Skalabilitas
Cluster HADOOP dapat dengan mudah diskalakan sampai batas tertentu dengan menambahkan node cluster tambahan dan dengan demikian memungkinkan untuk pertumbuhan Big Data. Selain itu, penskalaan tidak memerlukan modifikasi pada logika aplikasi.
• Fault Tolerance
Ekosistem HADOOP memiliki ketentuan untuk mereplikasi input data ke node cluster lainnya. Dengan begitu, jika terjadi kegagalan simpul gugus, pemrosesan data masih dapat dilanjutkan dengan menggunakan data yang disimpan pada simpul gugus lain.
Topologi Jaringan Di Hadoop
Topologi (Pengaturan) dari jaringan, mempengaruhi kinerja cluster Hadoop ketika ukuran cluster Hadoop tumbuh. Selain kinerja, kita juga perlu memperhatikan ketersediaan tinggi dan penanganan kegagalan. Untuk mencapai Hadoop ini, pembentukan cluster menggunakan topologi jaringan.
Biasanya, bandwidth jaringan adalah faktor penting untuk dipertimbangkan saat membentuk jaringan apa pun. Namun, karena mengukur bandwidth mungkin sulit, di Hadoop, jaringan direpresentasikan sebagai pohon dan jarak antara node pohon ini (jumlah hop) dianggap sebagai faktor penting dalam pembentukan cluster Hadoop. Di sini, jarak antara dua node sama dengan jumlah jarak mereka ke leluhur bersama terdekat mereka.
Hadoop cluster terdiri dari pusat data, rak, dan simpul yang benar-benar menjalankan pekerjaan. Di sini, pusat data terdiri dari rak dan rak terdiri dari node. Bandwidth jaringan yang tersedia untuk proses bervariasi tergantung pada lokasi proses. Artinya, bandwidth yang tersedia menjadi lebih sedikit saat kita pergi dari-
- Proses pada simpul yang sama
- Node yang berbeda pada rak yang sama
- Node pada rak berbeda dari pusat data yang sama
- Node di pusat data yang berbeda
Sumber
What is Hadoop? Introduction, Architecture, Ecosystem, Components